How to code Python with ChatGPT
By Christian Prokopp on 2023-01-29
Can ChatGPT help you develop software in Python? Let us ask ChatGPT to write code to query AWS Athena to test if and how we can do it step-by-step.

We start with a brief introduction to ChaptGPT and code generation. Then we attempt a real-world code problem with ChaptGPT. This will highlight its abilities and limits.
OpenAI ChatGPT for Code
If you have not done so, go to OpenAI's ChatGPT website, register for an account and login. You will see a screen similar to the one below after logging in.

The ease of use of ChatGPT is one of its success factors. You type your question or command in natural language, and it will answer human-like with generated text.
> What is ChatGPT?

One amazing feature of ChatGPT is its ability to respond to programming questions with code.
> Write a hello world program in Python.
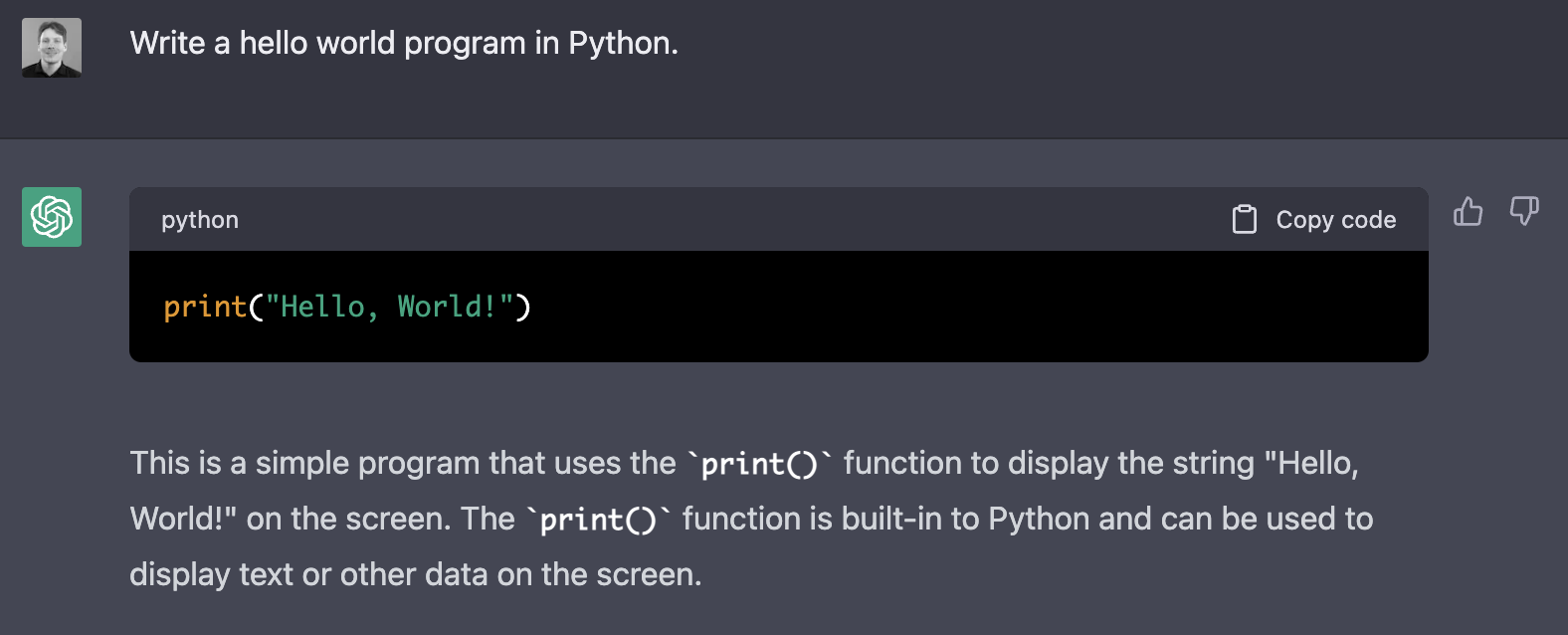
A useful capability of ChatGPT is its ability to respond to follow-up questions and modifications to previous questions.
> Move it into a function.
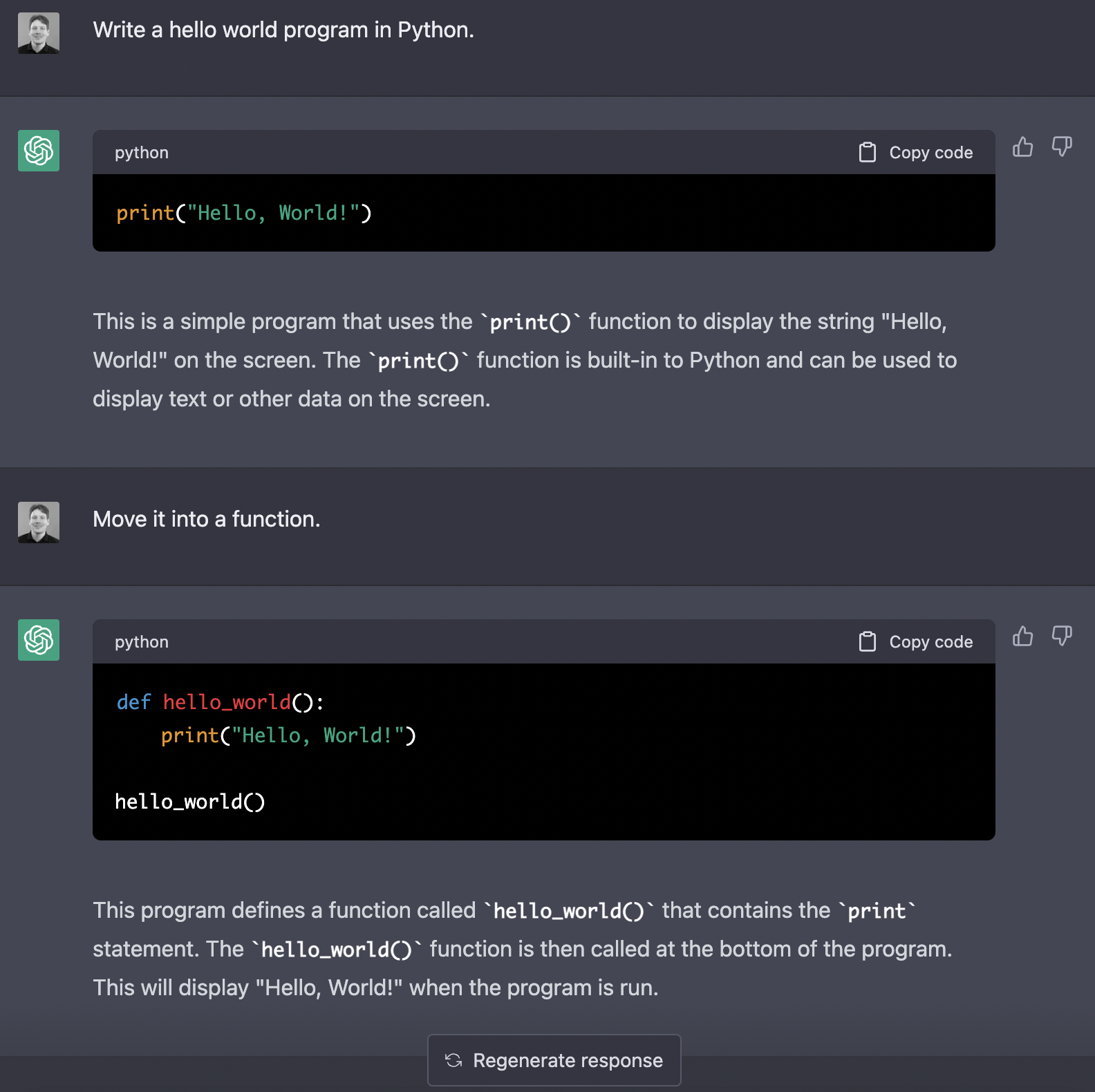
The model understood the reference of 'it' and what a Python function is and named it aptly. And if you are unhappy with a response, you can edit the question asked by clicking the edit icon to the right of your question. Or you can click the 'Regenerate response' button to give ChatGPT a chance to come up with a different answer.
While we will stick with Python for this example, it is noteworthy that ChatGPT can also generate other code in other languages.
> Turn it into JS code.
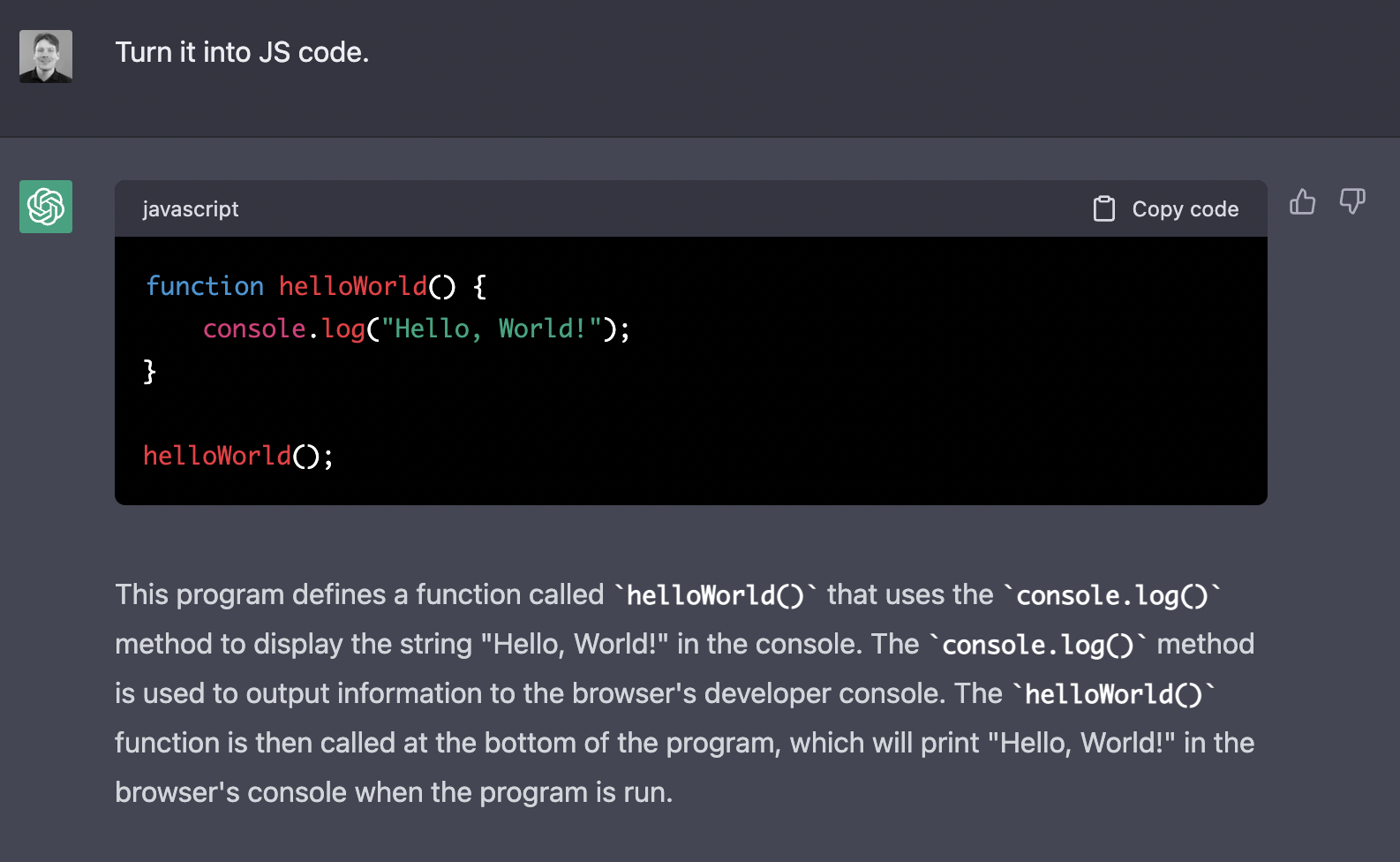
Apparently, twelve or more, according to the model itself.
> List the programming languages for which you can produce code.
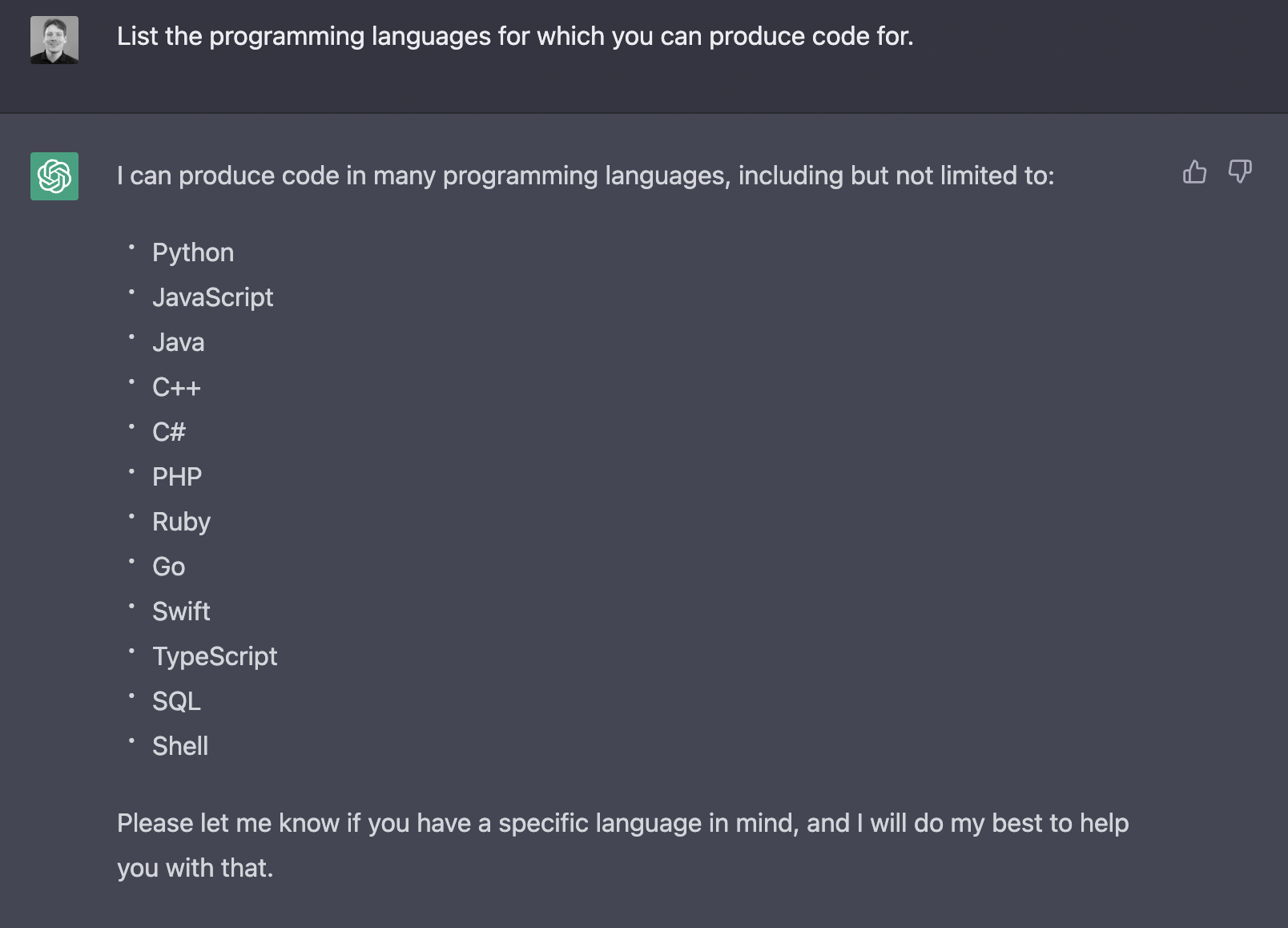
Having the right approach and avoiding some pitfalls is essential to using ChatGPT. Otherwise, you may waste your time or end up with bad code.
How to start coding in ChatGPT
You will need your usual tools like an IDE, terminal, code version control like git, etc. If you are new, a simple text editor or any IDE will do to start. Create your Python project and add an empty Python file.
Trying to get all aspects of the code into one question that ChatGPT will understand correctly is tricky. A good strategy for using ChatGPT is to ask it to solve a simple problem and then iterate with additional improvements in follow-up questions. The starting point can be a simple requirement you work on or an idea you want to explore a new technology or feature.
Query Athena with Python using ChatGPT
Let us use something that could come up in everyday development work. Write some reusable code we can use to query Athena. Athena is an AWS NoSQL store using Trino as a query engine and S3 as storage. Such code could be useful for Data Engineers, Data Scientists or Software Engineers. Importantly, it is achievable for ChatGPT and more challenging than reproducing a Hello World problem.
Click on the '+ New chat' button on the top left to open a clean context. Note your output will vary from mine.
> Write a Python function to query Athena.
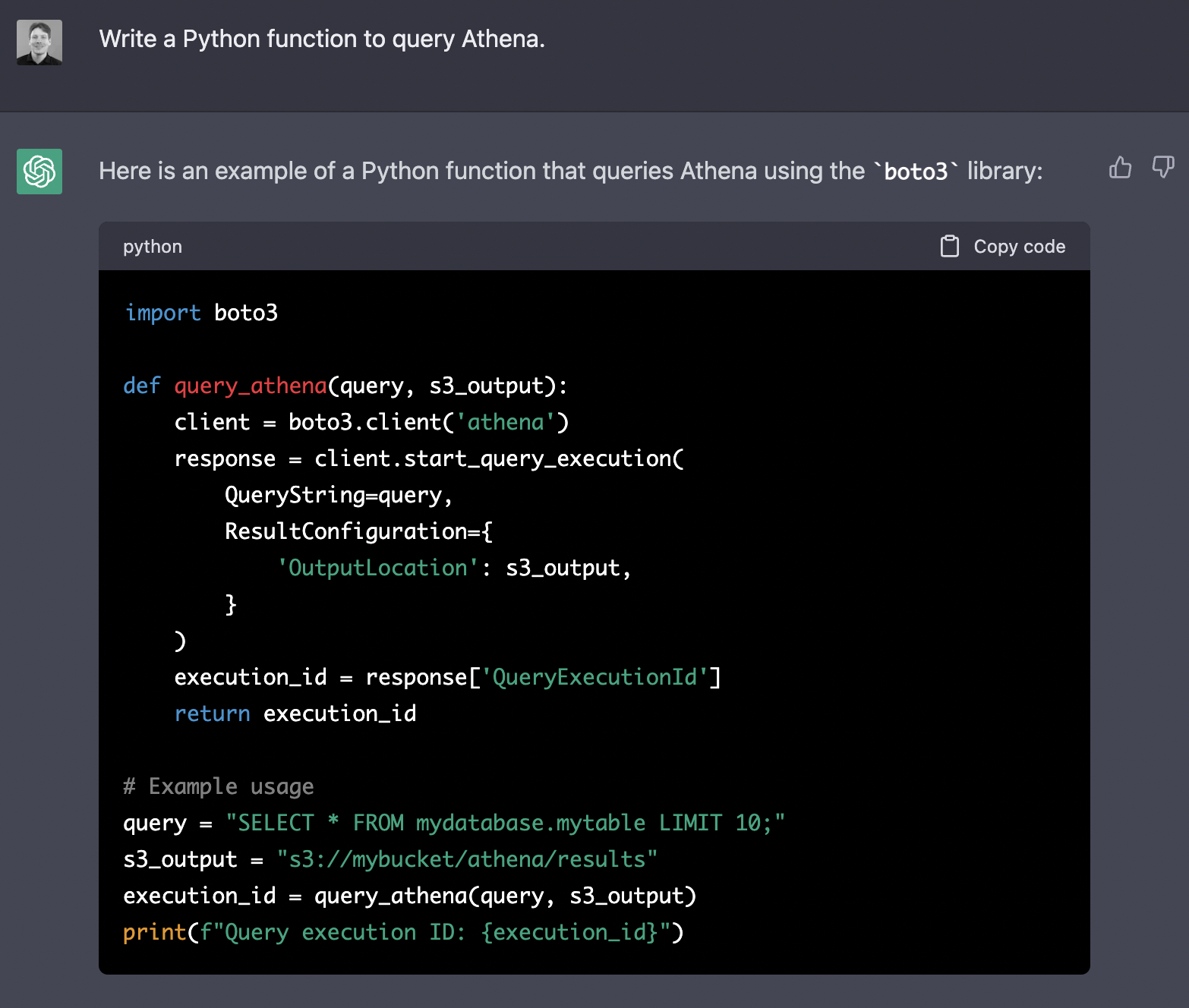
Besides the code, it provides helpful commentary to explain it. So far, we could easily get similar code using Google and Stack Overflow.

It becomes interesting as we refine the work. Let us move the database into a parameter instead of hardcoding it in the query.
> Pass the database as a parameter for the function and the query execution.
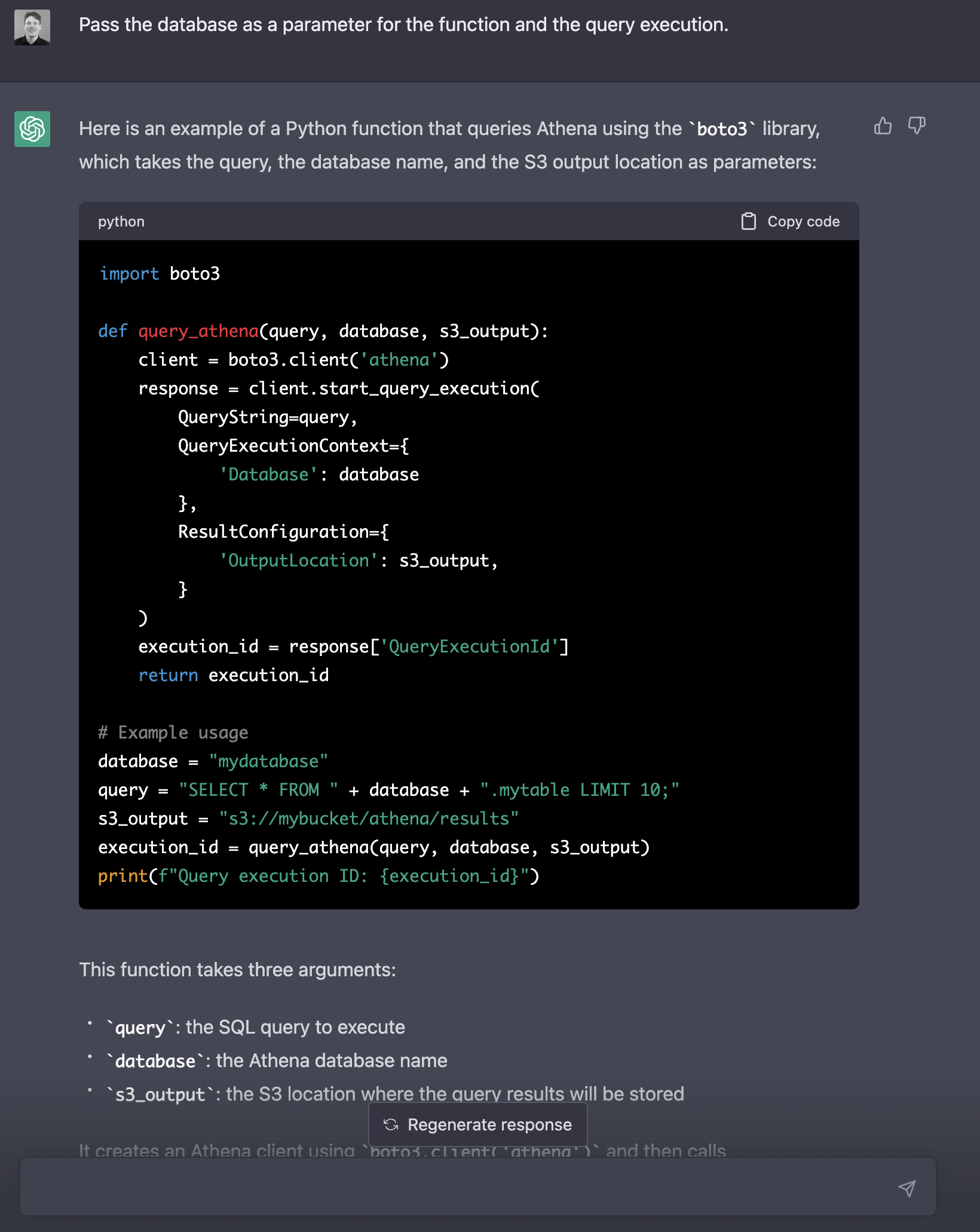
Of course, this will not work as an independent script, so we cannot test if the generated code works. Let us fix that so we can sense-check the output. We will get to unit testing later.
> Add a main function. Read the database, query and s3_output as named command line arguments.
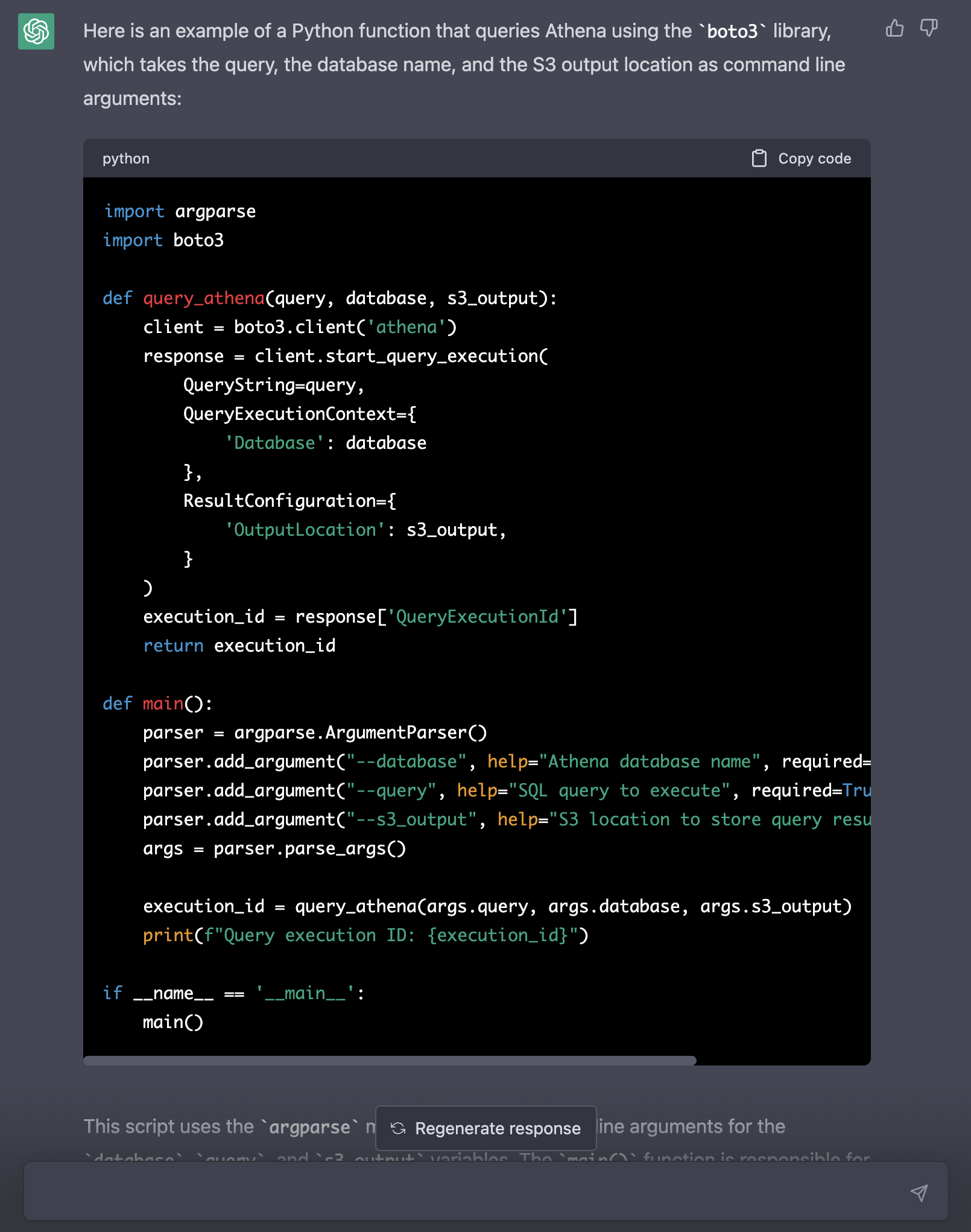

Assuming you have your AWS credentials set up, you could now copy the code into a Python file to try and query Athena from the CLI.
CLI > python scripts/chatgpt.py --database default --query "SELECT 1+1" --s3_output s3://somewhere
Traceback (most recent call last): ...
botocore.exceptions.NoRegionError: You must specify a region.
Clearly, ChatGPT missed the region parameter. Let us ask it to fix the error.
> Your code creates the following error: botocore.exceptions.NoRegionError: You must specify a region. Fix it.
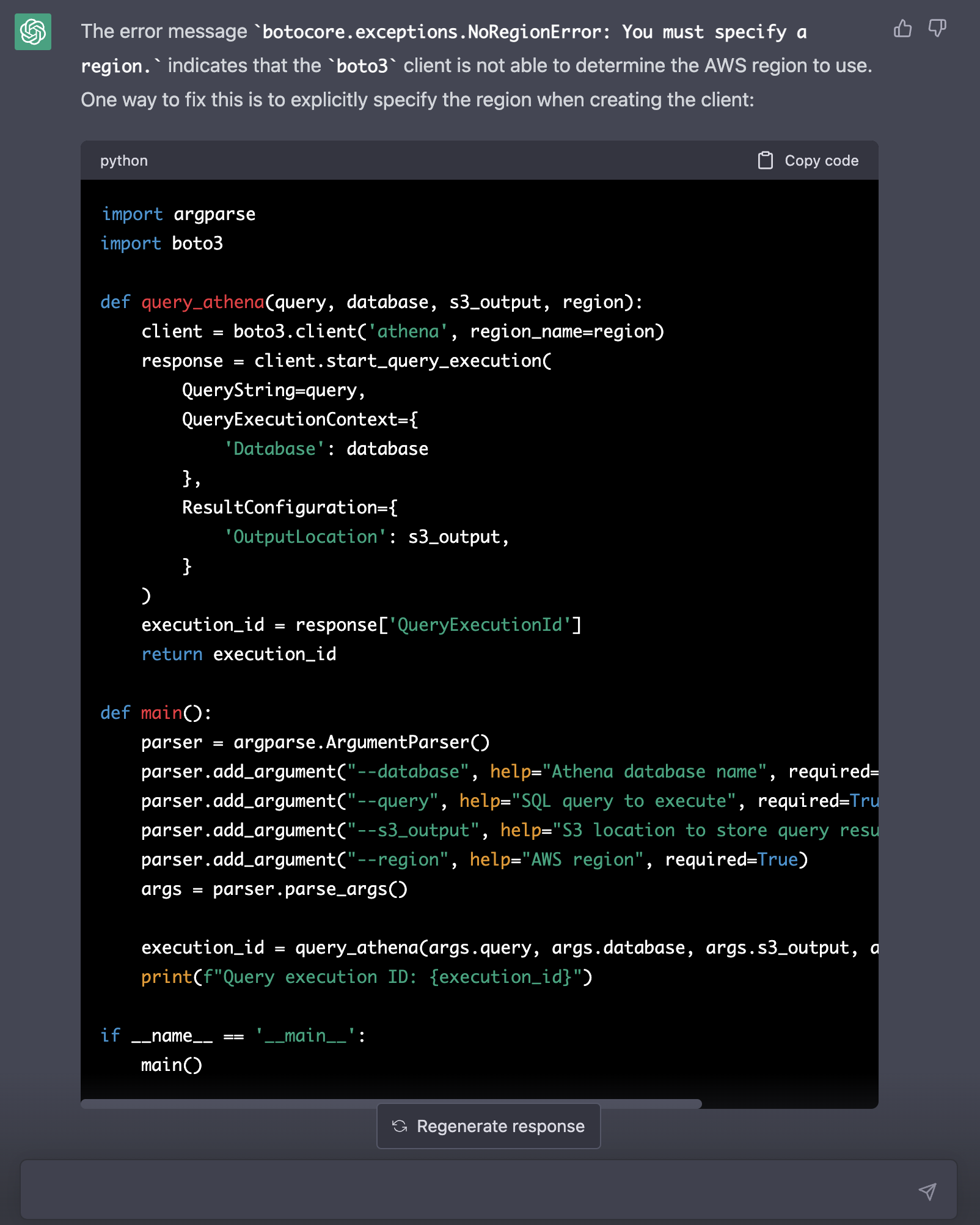
The code works. Adding the region allows the query to execute. But instead of the result, we only get the query execution ID printed.
> Let query_athena return the query result as a dictionary and print the returned result in the main function.
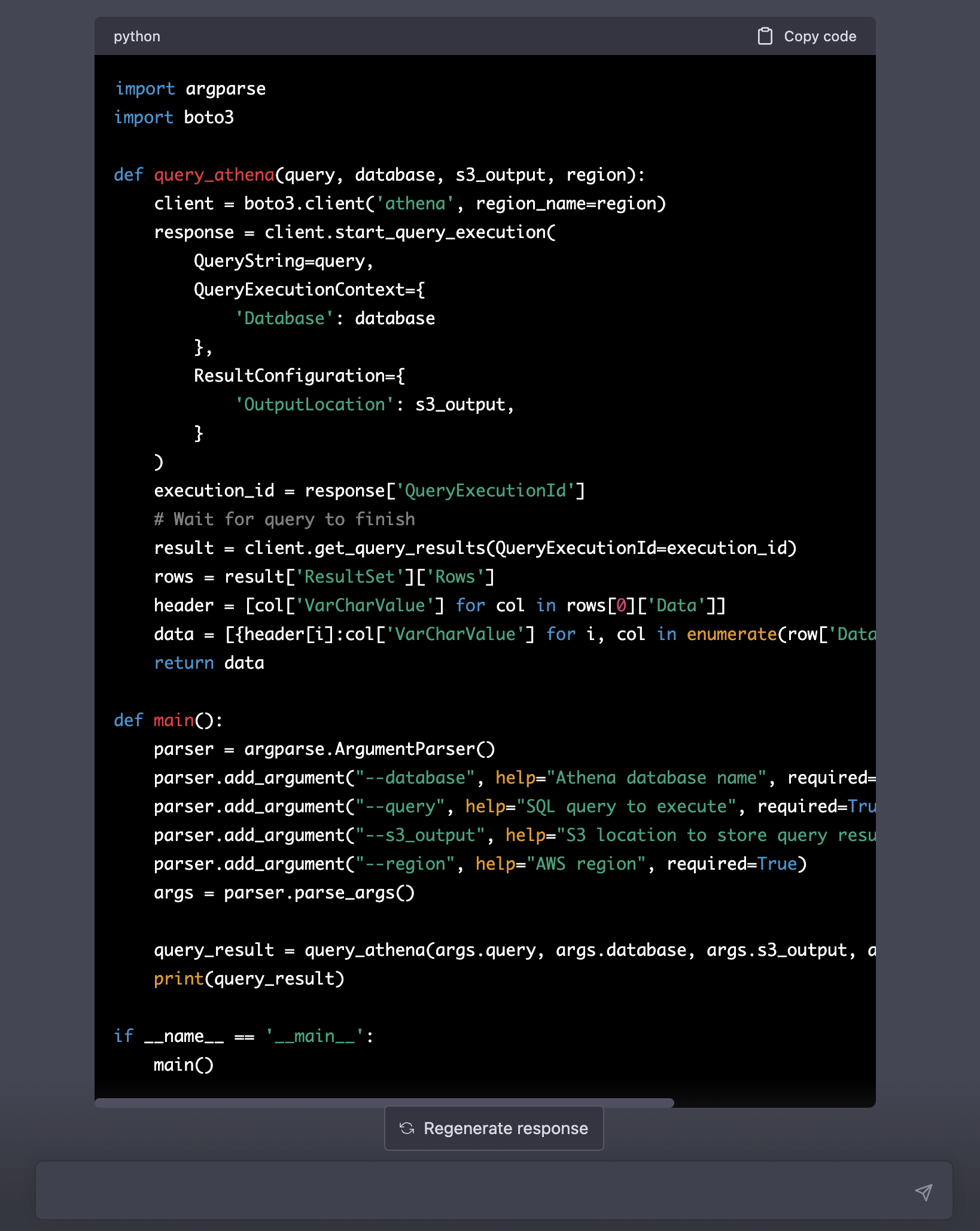
When we copy the code and run it, we have a new error, so let us ask it to be fixed too.
> Your code throws the error: botocore.errorfactory.InvalidRequestException: An error occurred (InvalidRequestException) when calling the GetQueryResults operation: Query has not yet finished. Current state: QUEUED Fix it.
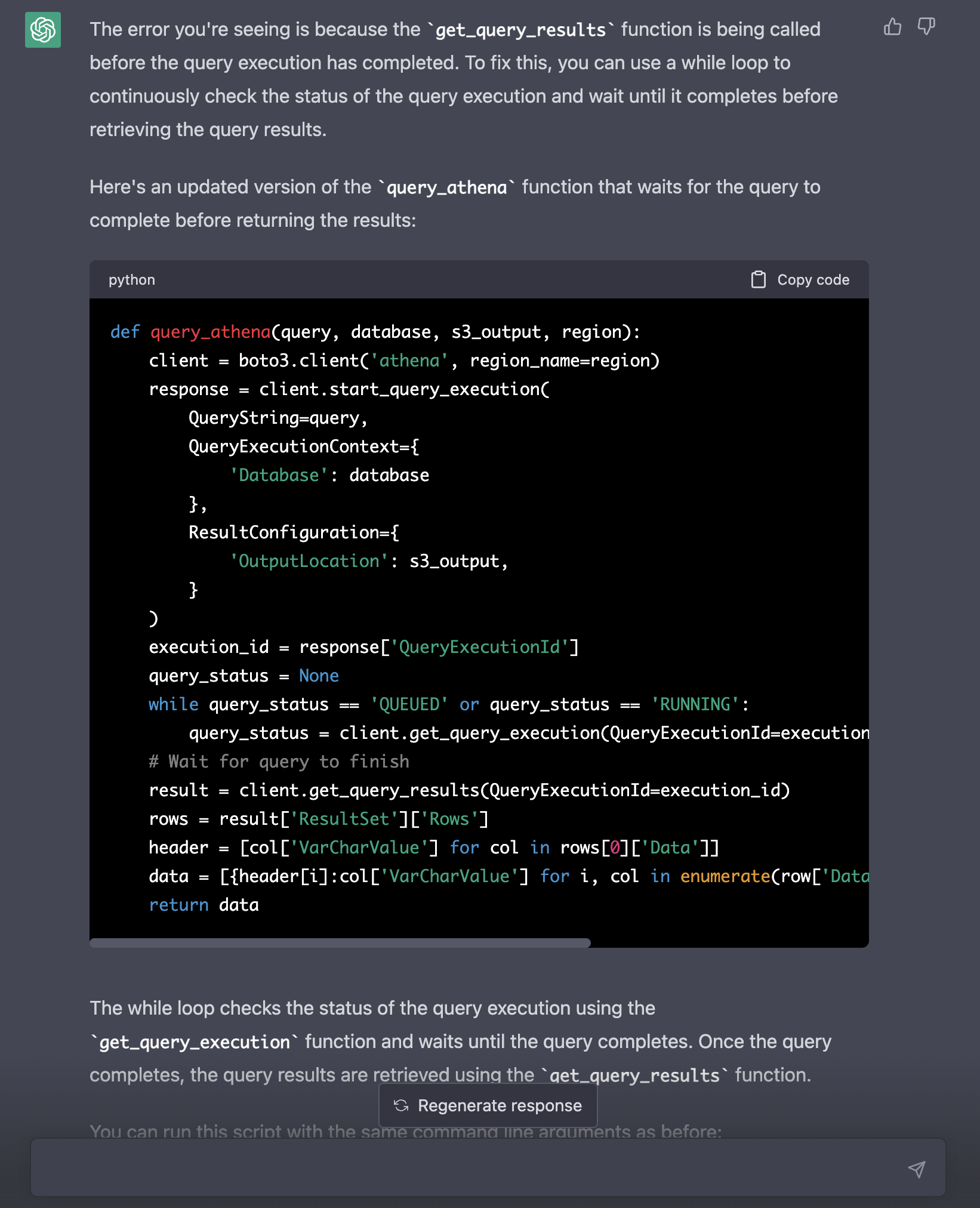
Experienced developers will spot a bug here. If we run the ChatGPT code, we will get the same error because the while loop tests for a condition that can never be true since the variable is set to None before the loop.
> Find the bug in query_athena and fix it.
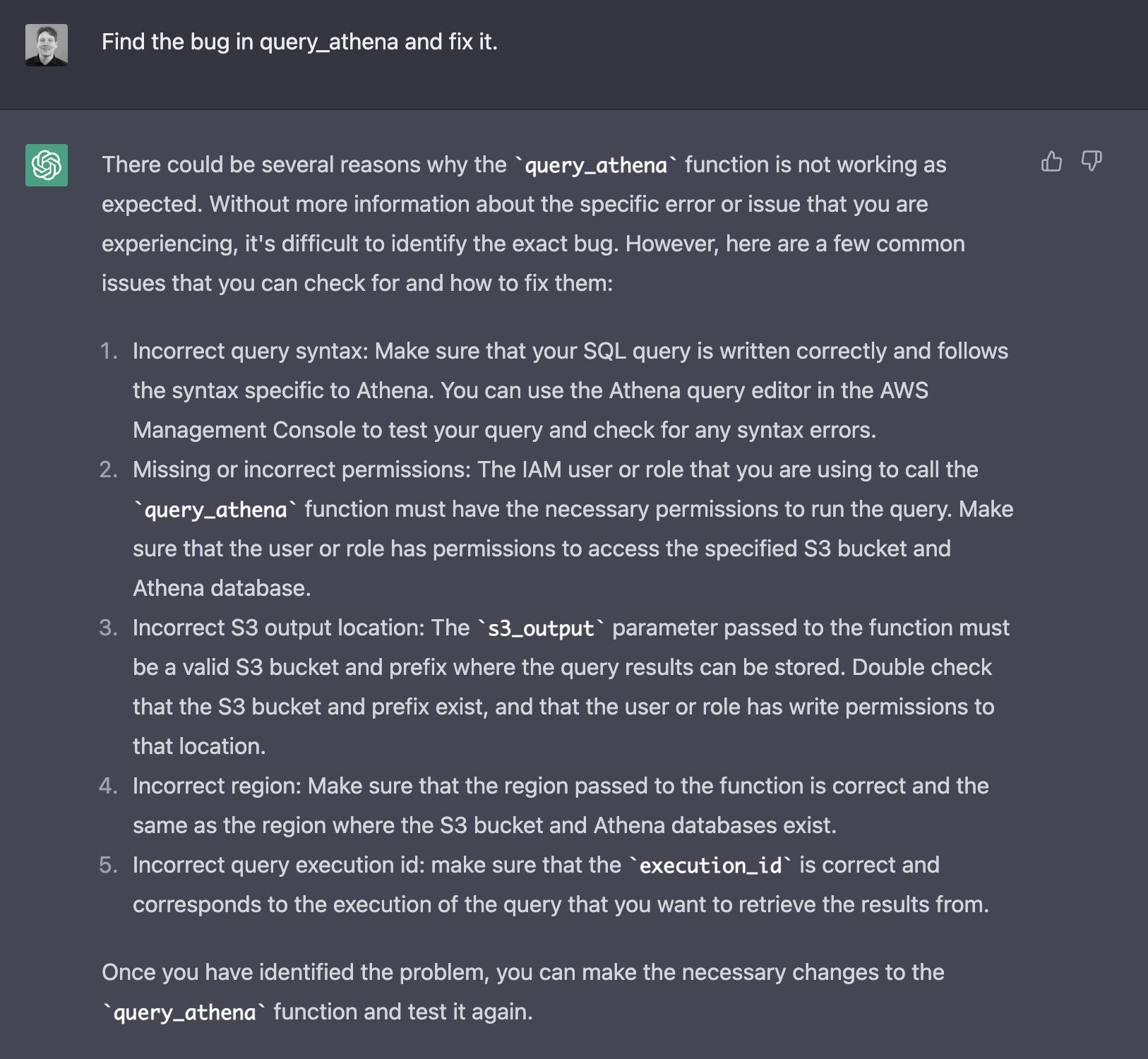
While it has some good suggestions, none are relevant, and it needs to understand what it did wrong without giving it a helping hand.
> There is a bug in the query_status while loop. It can never be true because it is set to None before the loop. Fix it.
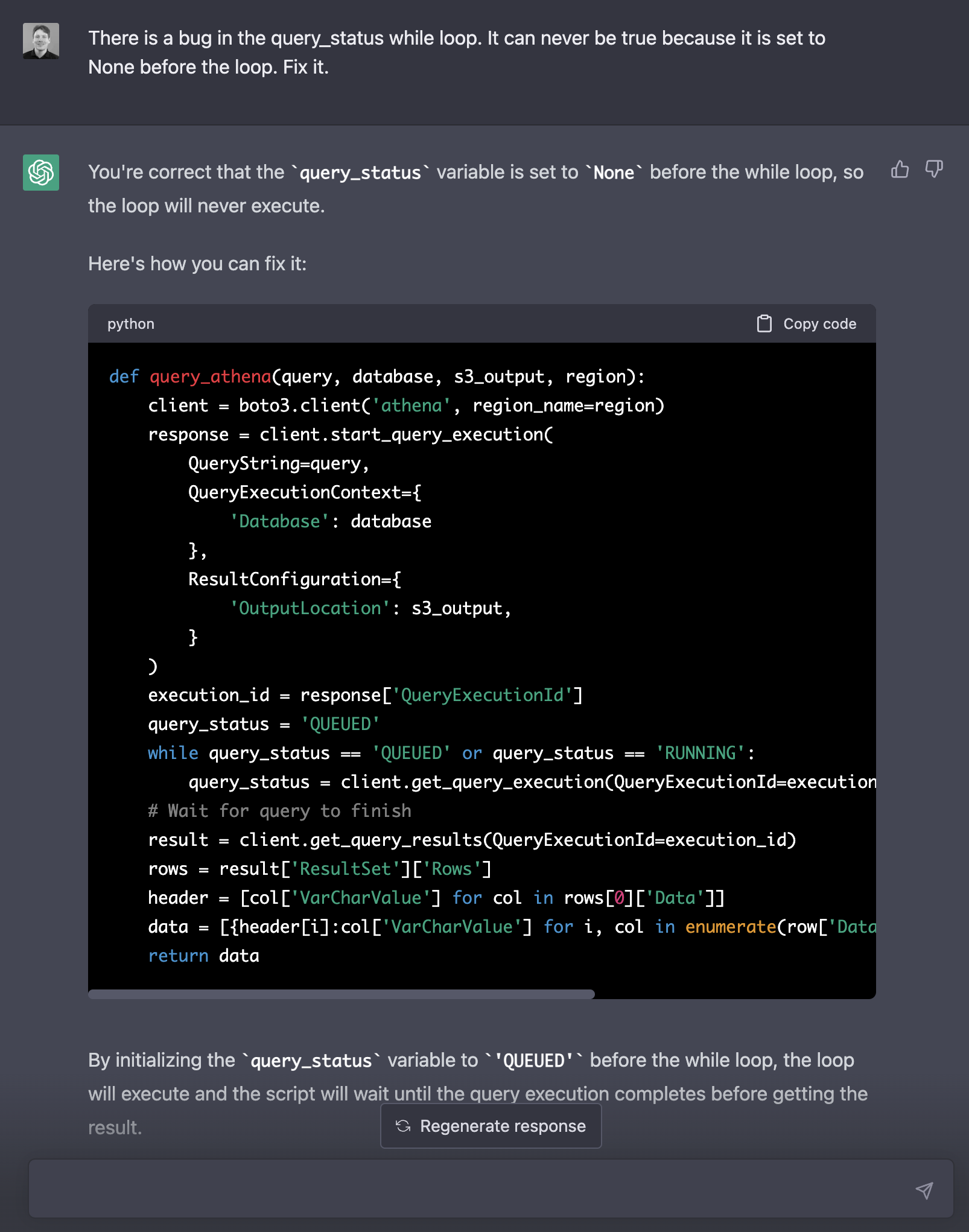
Better, the code works again. But the output is a list of dictionaries, e.g. each row is a separate dictionary. That is not easy to work with or store. Let us use a dataframe instead.
> Convert the query result in query_athena into a dataframe instead of a dictionary.
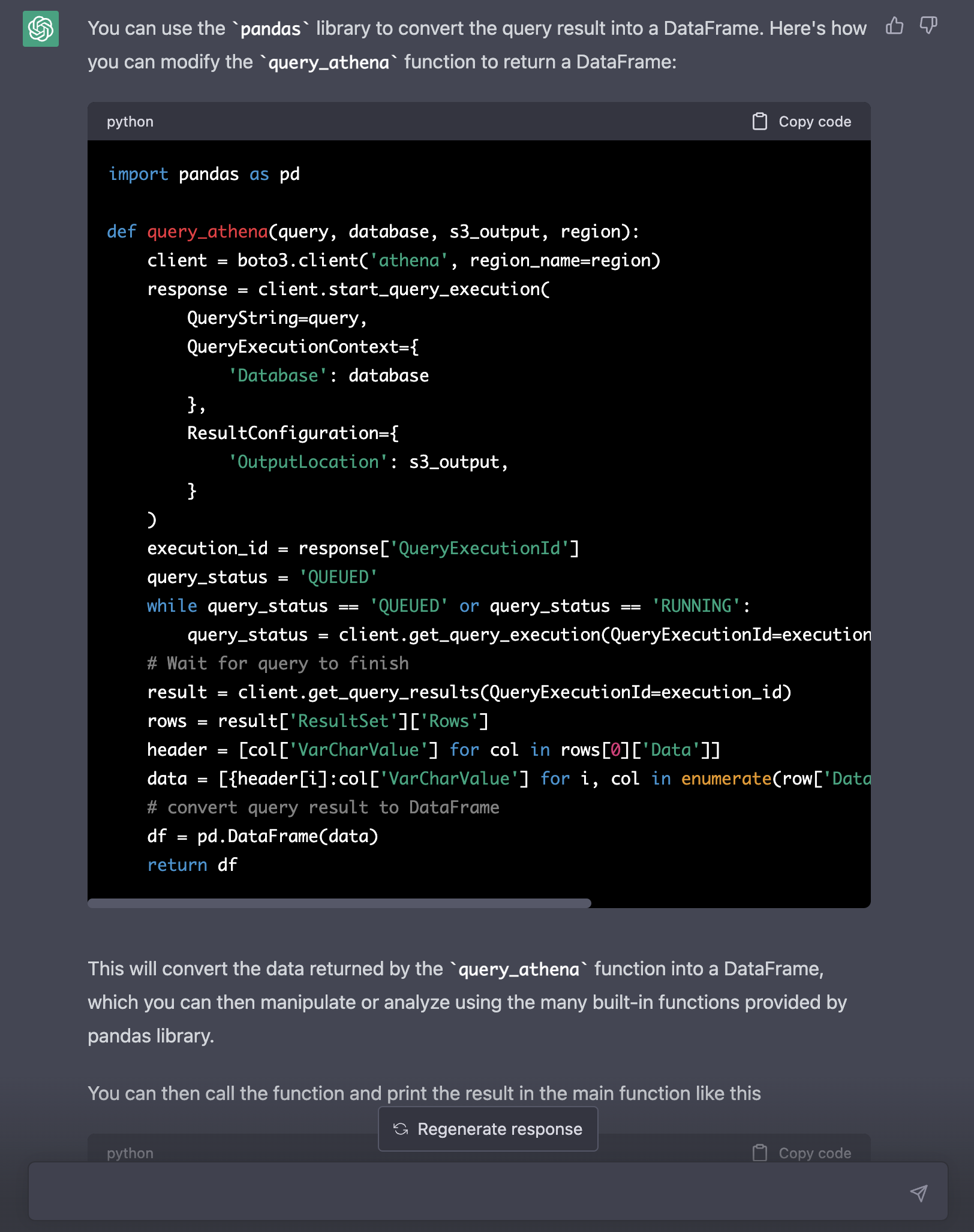
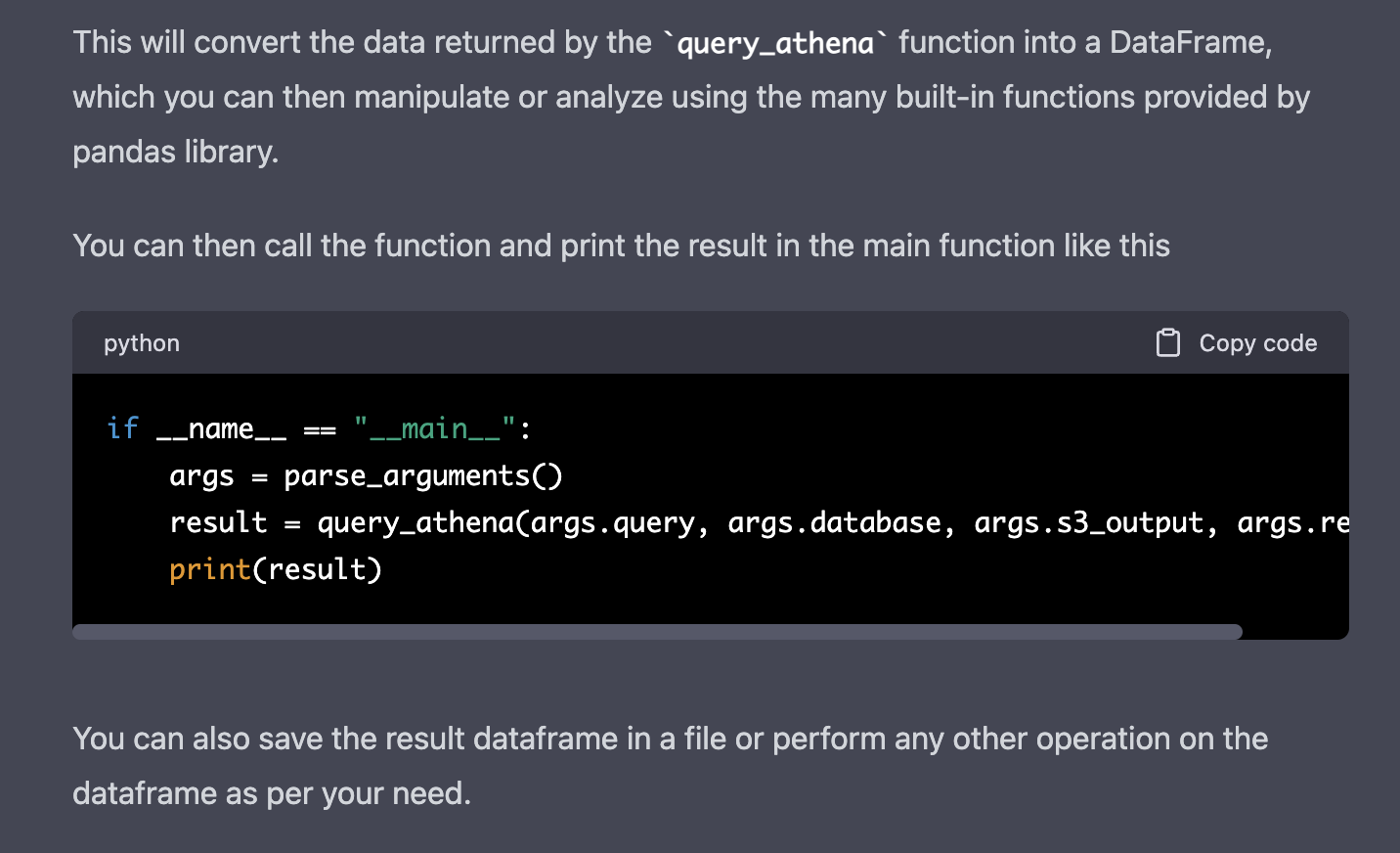
Unprompted, it also provided a 'new' main function. ChatGPT does reimagine the code every time, which allows for errors, resurfacing bugs or duplications. That can be confusing and break code. We will edit the main function as needed manually in our code instead.
We can see a few opportunities to move forward by playing around and taking a step back. Results of 1,000 or more rows only download partially. Large Athena results need pagination to download the whole. Furthermore, there is no unit testing, no type annotation, and no easy reuse if we want to use the code for multiple queries in an existing code base. Let us quickly try and fix some of these without going into each in detail.
> Add type annotation to query_athena.
[...]
> Add pagination to the query result handling to deal with results larger than 1000 rows.
[...]
> In the while NextToken loop only ignore the first row of the query result for the first result page but not for any of the following.
[...]
> Change query_athena to a singleton class called AthenaQuery that takes s3_output and region as parameters to the constructor. Let the constructor create and store a reusable Athena client connection. Put all the query execution and result transformation into a method called execute that takes the query and database as parameters.
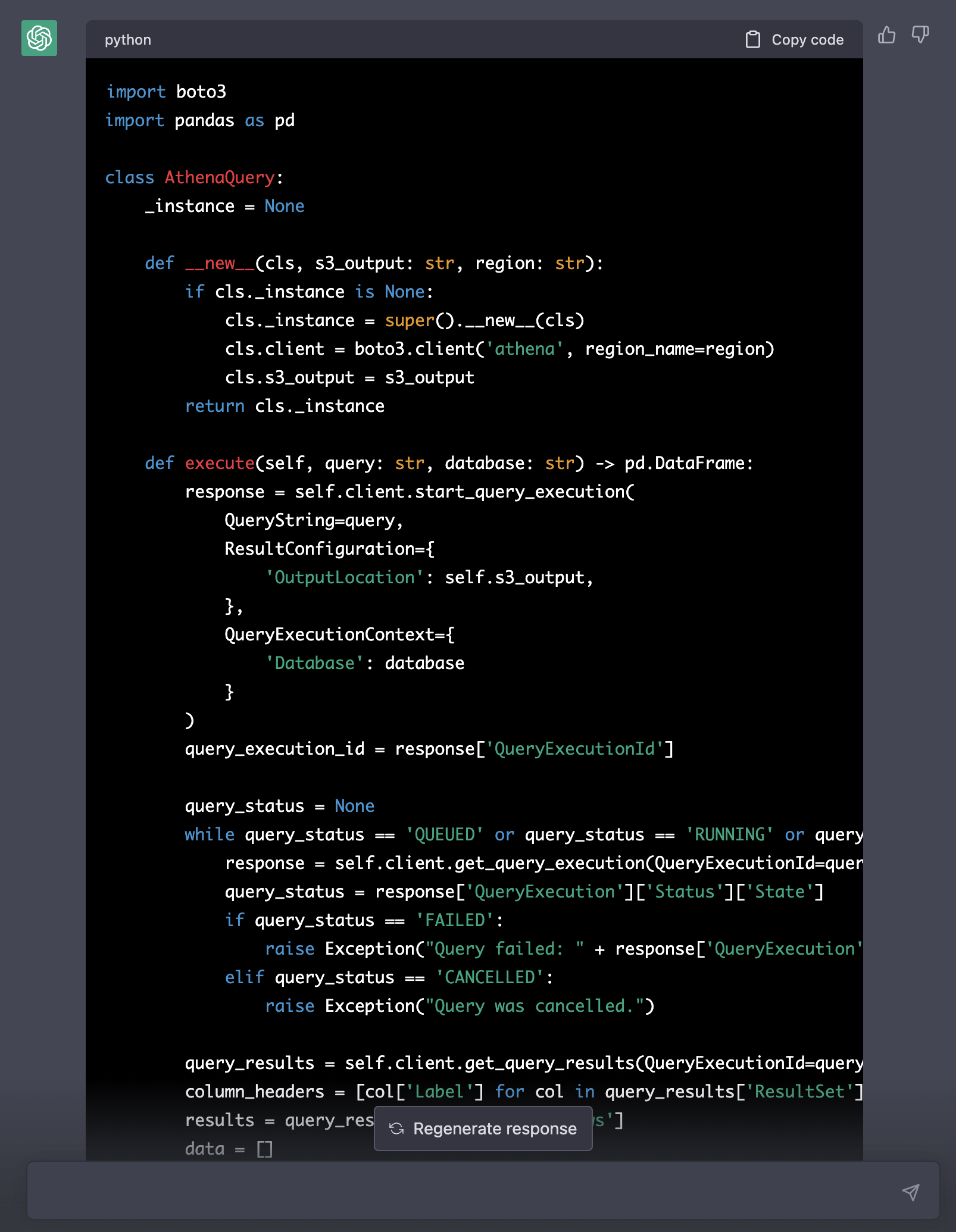

At this point, I asked ChatGPT a few times to refactor the execute method to break out some private methods. It led to the reintroduction of previous bugs and inefficient in-memory data movement. So I abandoned that step.
Looking at the execute method, we find it reintroduced storing data in an in-memory list of dictionaries before converting it into a dataframe. And it reintroduced storing the header as the first row of data. When I tried to prompt it to remove these, it started breaking further, moving around parameter order in the method signature and changing variable names.
Similarly, when I attempted to ask for a refactored __new__ method to accommodate an optional mockable client for easier unit testing, it started breaking the code in various ways. I have had luck with ChatGPT providing some decent unit tests in some circumstances but not this time.
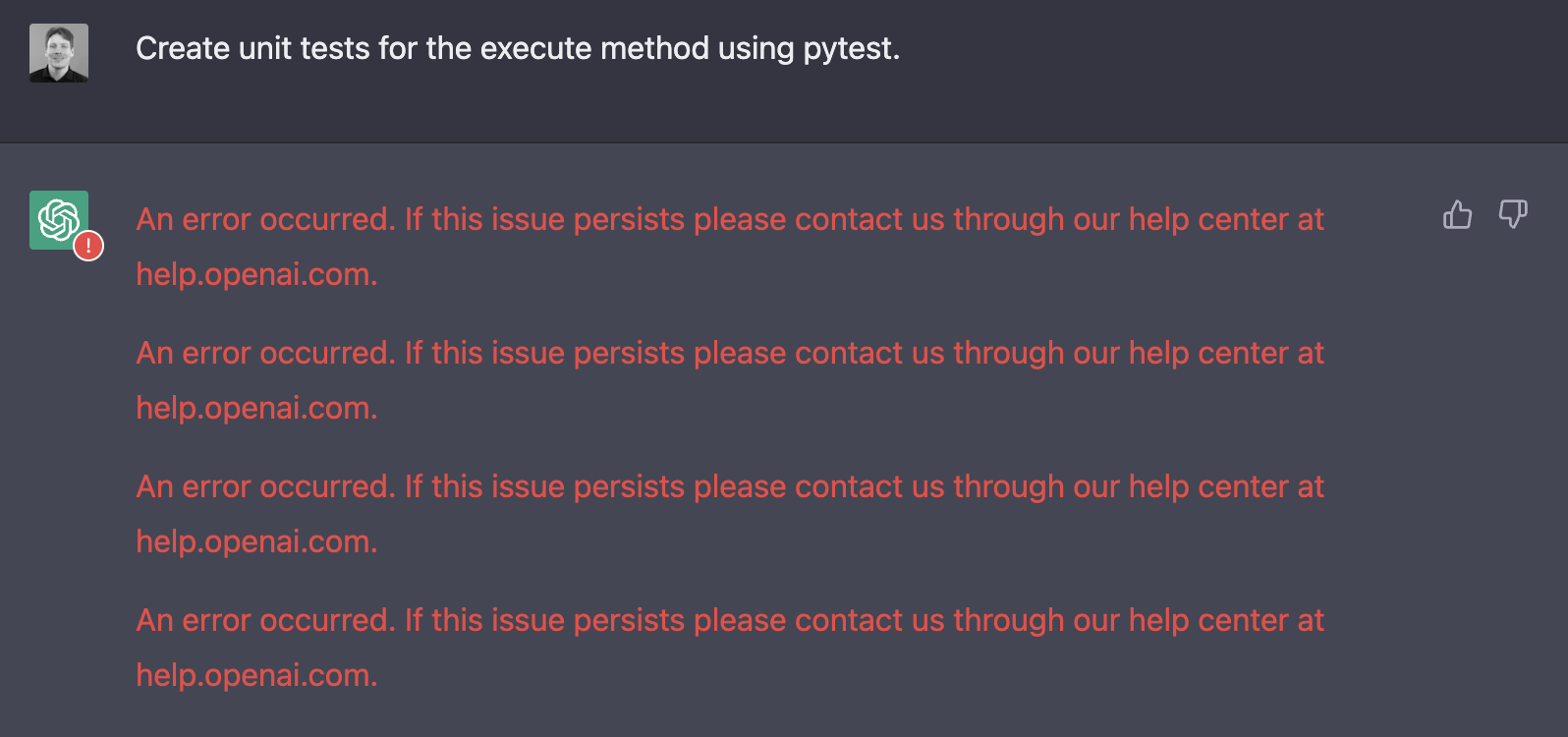
Sadly, eventually, the service stopped working and returned only error messages. So the how-to has to stop here. Hopefully, when it becomes a paid service, it will be more reliable.
ChatGPT code limitations
In a way, the issues this how-to ran into are an excellent example of the current limitations.
- Timeliness - the model's data is not as up-to-date as a search engine, so recent tools, libraries, releases, etc, may need to be added and not suggested.
- Hallucinations and inconsistency - the model may plug gaps with sensible sounding words or code. That could be data structures, libraries or keys that do not exist. Or it may just change names, ordering or anything else with every new step.
- Duplication - the model may combine (in isolation) reasonable steps or libraries, but that have duplicate effort, e.g. it might suggest compression of already compressed data. Also, it tends to repeat errors after a while despite prompts that corrected it previously.
- Simplistic - the model often needs to be prompted to improve or harden code and is biased towards simple examples without edge cases or production aspects considered.
- Superfluous and wrong - the model may make duplicate, unnecessary or plain harmful suggestions or code. It does not understand the logical dependency of code and may give generally good advice but to unsuitable specific circumstances.
- Size and complexity - the input and output of ChatGPT are limited. The exact details are confidential, but you run into them. For example, the output might cut off mid-code or sentence when it runs out of 'space'.
- Availability - while the service is in public trials, it is unreliable.
Summary
Today, I find correctness, complexity and length to be the key issue. If you can limit your interaction to a small function and scope, you might get something helpful or inspiring. But check every line and every statement.
Overall, it is a fascinating technology and gives us a glimpse into future software development tooling. Like documentation lookups on function signatures in IDEs, LLMs like ChatGPT could provide intelligent suggestions or code completions. But the output's usefulness and correctness need addressing first.
Christian Prokopp, PhD, is an experienced data and AI advisor and founder who has worked with Cloud Computing, Data and AI for decades, from hands-on engineering in startups to senior executive positions in global corporations. You can contact him at christian@bolddata.biz for inquiries.
Related Posts

How many words are 128k tokens?
2024-04-12
128k tokens are 96k words in English for ChatGPT 3.5 and 4. The ratio is estimated to be 0.75 words per token. However, the answer is not straightf...

Bing Chat argues and lies when it gets code wrong
2023-02-11
Microsoft could follow Google's $100bn loss. I tried the new Bing Chat (ChatGPT) feature, which was great until it went disastrously wrong. It even...

OpenAI GPT-3: Content spam or more?
2022-12-04
OpenAI's ChatGPT has made the news recently as a next-generation conversational agent. It has a surprising breadth which made me wonder, could Open...

One simple thing companies miss about their Data
2022-08-08
There is one simple thing most companies miss about their data. It has been instrumental in my work as a data professional ever since.

Free Amazon bestsellers datasets (May 8th 2022)
2022-05-10
Get huge, valuable datasets with 4.9 million Amazon bestsellers for free. No payment, registration or credit card is needed.

Bad Data: Nameless Amazon bestsellers
2022-05-03
Many Amazon marketplace customers know that its huge product catalogue has data quality issues. However, they might expect its top sellers, which t...