How to Build Training Datasets and Fine-tune ChatGPT
By Christian Prokopp on 2023-11-29
Large-language models (LLMs) are great generalists, but modifications are required for optimisation or specialist tasks. The easiest choice is Retrieval Augmented Generation (RAG) with in-context, which has become easier with OpenAI's custom GPTs. The hardest and most unattainable option is creating a specialist LLM from scratch. But you can achieve much of it by simply adjusting an existing LLM like ChatGPT, a process called fine-tuning. You can do that with open-source or commercial models like OpenAI's ChatGPT3.5 and soon ChatGPT4. For fine-tuning to work and work well, you need a training dataset tuned to the task you want to address. It requires thought and structure and can be slow and costly to create manually. Luckily, you can use LLMs to create it too.

Why Fine-tune?
OpenAI has documentation going into detail on how and when to perform fine-tuning. It improves:
- Cost, e.g., shorten prompts or use cheaper/smaller models
- Style, tone, format and quality
- Output reliability
- Following complex prompts
- Edge cases
- Tasks or new skills exceeding prompt engineering
However, as a rule, attempt to optimise your results with prompt engineering before fine-tuning. And, from experience, fact retrieval tasks are better served by RAG than fine-tuning. However, combining the two could beat either solution in the future.
This post will use OpenAI's ChatGPT to demonstrate the process. Their documentation provides an example of fine-tuning training data:
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already."}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?"}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters."}]}
It is a simple JSONL, a list of JSON objects in a text file. The system role is optional, and it can be reduced to question-and-answer pairs. We can take inspiration from Frequently-Asked-Questions (FAQs) when generating our dataset as a template. A FAQ-like structure can be easily created using LLMs like ChatGPT3.5 or ChatGPT4 if you have a corpus of text you want to train a model on. One benefit of fine-tuning is creating training data using ChatGPT4 to train ChatGPT3.5. In an ideal scenario, it results in GPT4 performance with GPT3.5 costs since the querying costs of the deployed model usually dwarf the training dataset generation and fine-tuning.
ChatGPT Fine-tuning Costs
Let us calculate an example to demonstrate the potential cost savings using OpenAI's API pricing. Let us assume an input corpus of 1 million tokens, which equates to roughly 1,500 pages of single-spaced English text, as the source corpus. Further, assume it converts into 500 thousand tokens of training data. Creating the training dataset with gpt-4-1106-preview would cost USD 10 for input ($0.01/1K tokens) and USD 15 for completion ($0.03/1K tokens). Fine-tuning of gpt-3.5-turbo would cost USD 4 ($0.0080/1K tokens) for a total of USD 29. We can expect some overhead, occasional API issues and preceding exploratory work so the final amount would be higher, but the magnitude is indicative.
Querying a fine-tuned gpt-3.5-turbo is more expensive than its default but cheaper than gpt-4-1106-preview. Let us assume a ratio of three to one between input and completion tokens for queries, which results in a blended cost of USD 0.00375/1k tokens (fine-tuned gpt-3.5-turbo) vs USD 0.015/1k tokens (gpt-4-1106-preview) or 4x. To illustrate this further, let us assume one hundred active users making ten 4k token queries per day. In this scenario, the difference would be USD 450/month vs USD 1,800/month API costs.
Training Dataset and Prompt
One of the tremendous benefits of LLMs is the ability to manually try many ideas out in plain text and experiment with prompts, adapting ideas quickly. Before you write a line of code to build anything like this, use the ChatGPT website or API playground and try it out. You can use the prompt below and head to Wikipedia to copy some text. Hint: click the edit button on the top and copy the markdown version of the Wikipedia article. Markdown is a great intermediate format that LLMs and humans alike process well.
For the prompt, we provide a description, example, and reinforcement to only output valid JSONL. You could replace the example question and answers with placeholders to save input tokens, which would also work. A benefit of a lengthy example is that it implicitly biases the LLM's output to a detailed answer. The alternative is an explicit description. You can also use short Q&A pairs, but be aware that the model will replicate the brevity.
Turn the below article into a FAQ in JSONL format like this:
```
{"question": "What's the capital of France?","answer": "The capital of France is Paris. It's not only the country's largest city but also a global hub for art, fashion, gastronomy, and culture. Its 19th-century cityscape is crisscrossed by wide boulevards and the River Seine. Paris is known for its cafe culture, and landmarks like the Eiffel Tower, Notre-Dame Cathedral, and the 12th-century, Gothic Sainte-Chapelle. The city is also famous for its museums and galleries, such as the Louvre Museum and the Musée d'Orsay. Paris has been a thriving metropolis and a center of arts and learning for over 2,000 years."}
{"question":"How far is the Moon from Earth?","answer":"The average distance from the Moon to Earth is about 238,855 miles (384,400 kilometers). This distance can vary slightly due to the Moon's elliptical orbit. At its closest point, known as perigee, the Moon is about 225,623 miles (363,104 kilometers) away. At its farthest point, or apogee, it's about 252,088 miles (405,696 kilometers) from Earth. It takes about 1.3 seconds for light to travel from the Moon to Earth. This distance has been confirmed by various methods, including laser ranging experiments using reflectors left on the Moon's surface by the Apollo missions."}
...
```
The output must be:
- only the JSONL, no text, comments or other information
- valid JSONL
---
<enter the content here>
Choose the Training, validation, and test data sets article on Wikipedia, click edit, and copy the markdown text.
Combining the prompt and the markdown text on the ChatGPT4 web UI gives us a good first result.
{"question": "What is machine learning?", "answer": "Machine learning is the study and construction of algorithms that can learn from and make predictions on data. These algorithms build a mathematical model based on input data to make data-driven predictions or decisions."}
{"question": "What is a training data set in machine learning?", "answer": "A training data set is a collection of examples used to fit the parameters of a model, such as the weights of connections between neurons in artificial neural networks. It's used during the learning process to adjust the model based on the comparison of the model's output and the target for each input vector."}
{"question": "What is a validation data set in machine learning?", "answer": "A validation data set is used to provide an unbiased evaluation of a model fit on the training data set while tuning the model's hyperparameters. It helps in regularization by early stopping to prevent overfitting."}
{"question": "What is a test data set in machine learning?", "answer": "A test data set is used to provide an unbiased evaluation of a final model fit on the training data set. It's independent of the training and validation sets and follows the same probability distribution as the training data set."}
{"question": "Why are different data sets used in machine learning?", "answer": "Different data sets are used in machine learning to improve the model's ability to generalize to new data. Training, validation, and test sets help in fitting the model, tuning hyperparameters, and evaluating the final model performance, respectively."}
{"question": "What is overfitting in machine learning?", "answer": "Overfitting in machine learning occurs when a model learns the training data too well, capturing noise and fluctuations that do not apply to new data. This results in poor generalization to unseen data."}
{"question": "What is early stopping in machine learning?", "answer": "Early stopping is a form of regularization used in machine learning where training is stopped as soon as the error on the validation data set begins to increase, indicating overfitting."}
{"question": "What does it mean to tune hyperparameters?", "answer": "Tuning hyperparameters in machine learning involves adjusting the parameters that govern the model's architecture and learning process, such as the number of layers in a neural network, to improve performance."}
{"question": "What is the difference between a validation data set and a test data set?", "answer": "The validation data set is used to tune hyperparameters and avoid overfitting during the model training process, while the test data set is used to assess the performance of the final model on new, unseen data."}
{"question": "What is cross-validation in machine learning?", "answer": "Cross-validation is a technique in machine learning where a data set is split into several training and validation sets to assess model performance. It provides more stable results and uses all available data for training."}
Two hurdles you will encounter when moving this into software using the API are the LLMs' tendency not to exhaust their completion window and the limited length of the completion window. Importantly, for the latest GPT4 with 128k token context size, the completion window is limited to only 4k! There are ways around both issues - to a degree.
First, the tendency to limit the length of lists produced by LLMs can be circumvented by asking for lists of lists. Prompting something like provide ten lists of ten items each works well. But then you have to do post-processing to recombine the list, and more importantly, you will likely experience the output being cut off at the 4k limit and invalid JSON(L). You will need to code a logic that detects if a line is incomplete and drops it from the result.
Second, to cover the content fully, you can right-size the input corpus into small enough documents. Or build complex logic and prompts to retry long documents until Q&A pairs have covered all content. You have to decide case by case but right-sizing the input might be easier than dealing with long documents, overlapping Q&As and how they may affect the training. Of course, if the content does not lend itself to splitting you may have no choice.
Once you have mastered this and prepared input data as text or markdown documents, you can query the API with your corpus and collect a large list of Q&A pairs. Combine all Q&As into a large set and split it for training and validation. Do not use the same data in both sets, avoid duplicates and large overlaps in Q&A pairs. For your final fine-tuned version, you can use all the data for training since the validation is only used for your benefit to show metrics and help you refine the input data.
ChatGPT fine-tuning
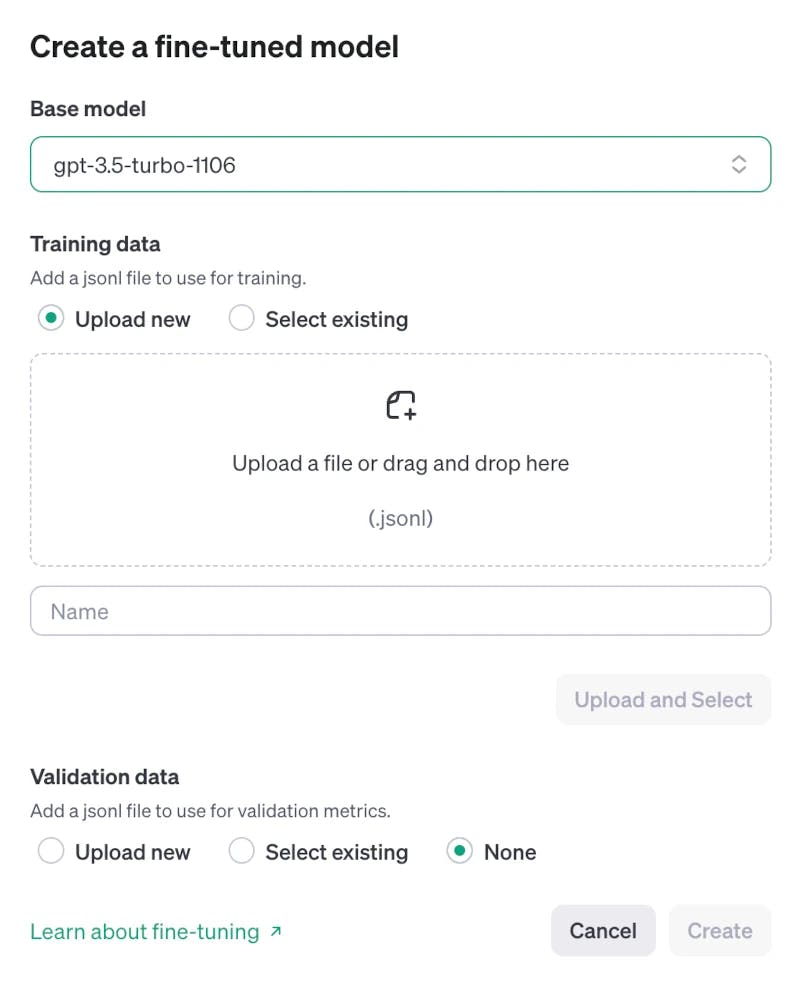
The training and validation data is uploaded as JSONL files. Use the website's user interface or API. Provide a large enough (10-30%) validation file while you experiment with your dataset generation to get meaningful metrics and compare how well things went between runs.
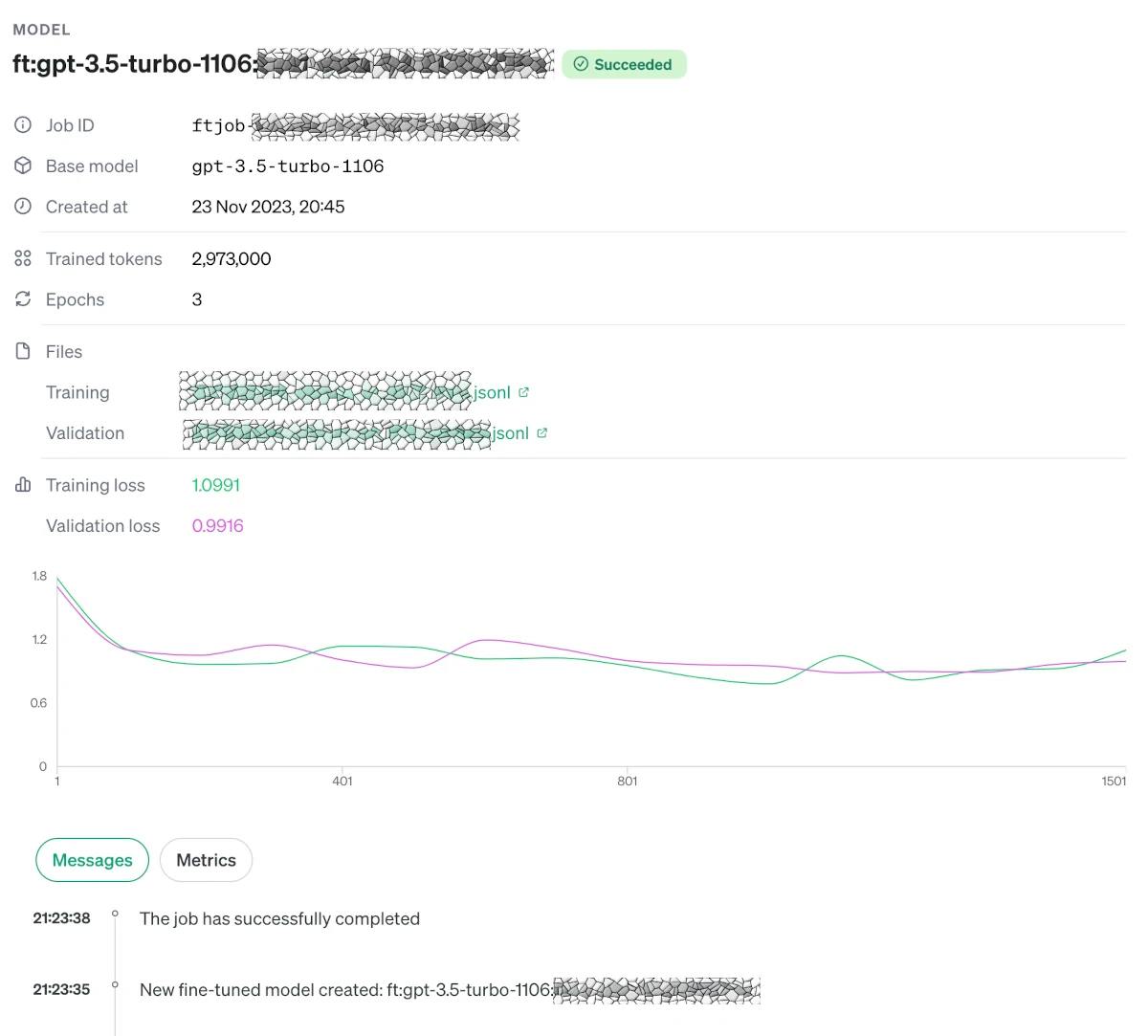
The time for the files to be submitted and a job to kick off can be minutes, and the fine-tuning can take hours depending on the size and presumably OpenAI utilisation. The UI will give you feedback and the latest metric regularly.
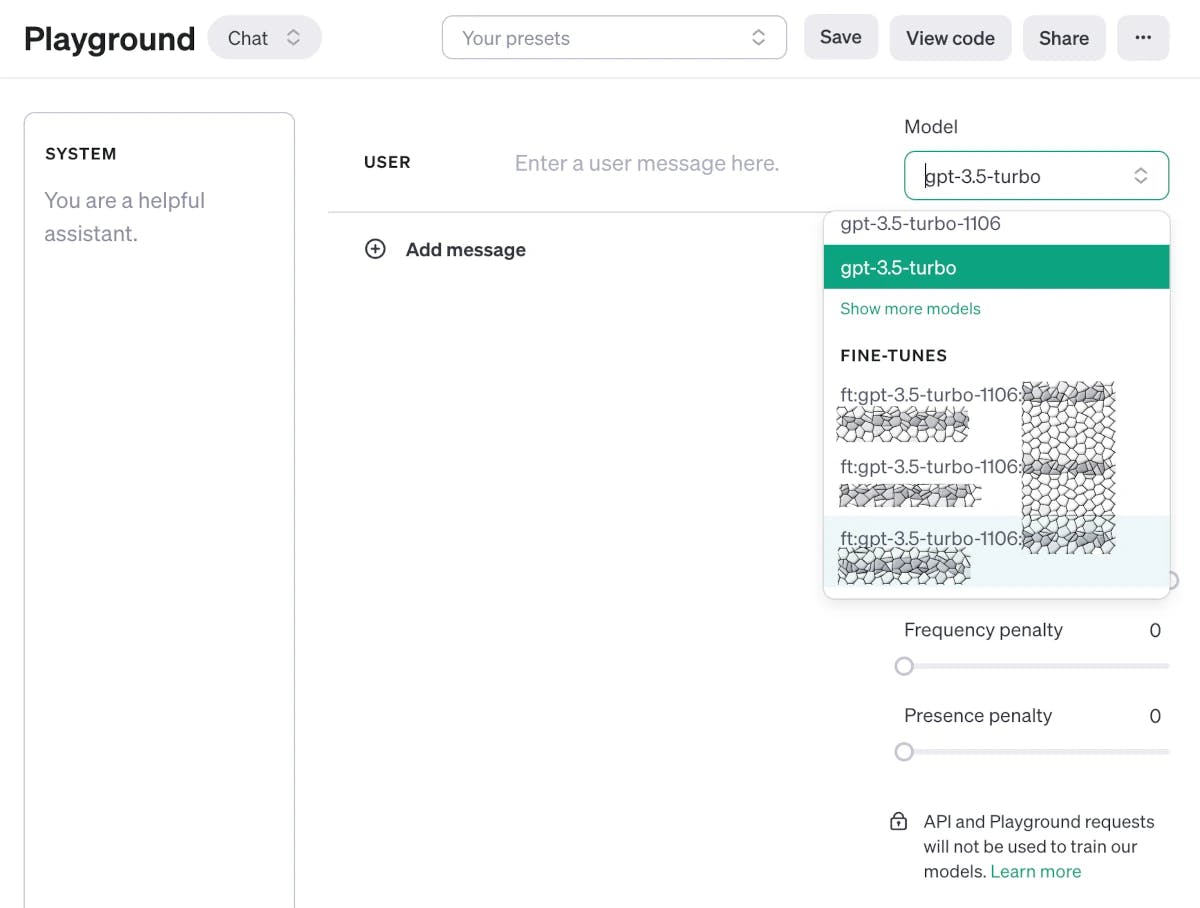
Finally, you can try out the fine-tuned model in the playground. Select Chat and then your model and the desired parameters before querying it. Of course, you can also use it via the API and roll it out for your use-case.
Conclusion
Fine-tuning Large Language Models (LLMs) like ChatGPT with specialised training datasets is an affordable and powerful way to tailor these generalist models for specific tasks or styles. It should not be your first choice but it is not as hard or expensive as you may think. While creating bespoke LLMs from scratch is out of reach for most, fine-tuning an existing model like OpenAI's ChatGPT3.5 or the upcoming ChatGPT4 is an accessible option that can yield significant improvements in performance and cost.
Christian Prokopp, PhD, is an experienced data and AI advisor and founder who has worked with Cloud Computing, Data and AI for decades, from hands-on engineering in startups to senior executive positions in global corporations. You can contact him at christian@bolddata.biz for inquiries.
Related Posts

How many words are 128k tokens?
2024-04-12
128k tokens are 96k words in English for ChatGPT 3.5 and 4. The ratio is estimated to be 0.75 words per token. However, the answer is not straightf...

Free Amazon Product and Bestseller Data
2024-04-11
Today, we release a massive dataset for non-commercial use, i.e. research or personal projects. The dataset covers Amazon product data for all of 2...

Introducing Tax Shrink
2024-03-14
Tax Shrink is a new online tool that helps owner-operators of Limited companies in the UK calculate and visualise the ideal salary-to-dividend rati...

How to code Python with ChatGPT
2023-01-29
Can ChatGPT help you develop software in Python? Let us ask ChatGPT to write code to query AWS Athena to test if and how we can do it step-by-step.

No, ChatGPT is not 10x-ing developer performance
2023-01-25
ChatGPT and similar language models have recently been gaining attention for their potential to revolutionise code generation and enhance developer...

Hard work is not appreciated!?
2022-05-30
Your hard work is not appreciated. So why should you still do it? There is a good reason.